robots.txt是任何搜索引擎優(yōu)化的重要組成部分,也是SEOer的重要一課。 但是,有時候robots.txt文件會被網(wǎng)站優(yōu)化師SEOer忽視。 無論你是否剛剛起步,或者你是一個優(yōu)化老手,都需要知道robots.txt文件應該怎樣寫。 那么,我們先來了解: robots.txt文件可以用于各種各樣的事情。 例如從讓搜索引擎知道去哪里找到你的網(wǎng)站站點地圖、告訴他們哪些頁面不需要抓取,以管理網(wǎng)站爬行預算。 搜索引擎會定期檢查網(wǎng)站的robots.txt文件,看看是否有任何抓取網(wǎng)站的說明。我們稱這些特別的說明為“指令”。 如果沒有robots.txt文件或者沒有適用的指令,搜索引擎將抓取整個網(wǎng)站。 Okay,那什么是爬行預算(Crawl Budget)? 簡單解釋下: 谷歌和其他搜索引擎一樣,他們只有有限的資源可用于抓取和索引你網(wǎng)站的內(nèi)容。 如果你的網(wǎng)站只有幾百個網(wǎng)址,那么Google應該可以輕松抓取到所有網(wǎng)頁并將其編入索引。 但是,如果網(wǎng)站很大,例如電子商務網(wǎng)站,有數(shù)千個包含大量自動生成的網(wǎng)頁(如搜索頁),那么Google可能無法抓取所有這些網(wǎng)頁,你將失去許多潛在的流量和可見性。 所以我們要通過設(shè)置robots.txt文件用于管理網(wǎng)站爬行預算。 谷歌表示: 那些低價值的網(wǎng)址就比如像搜索頁一類的頁面。生成太多這些頁面,谷歌蜘蛛如果去爬行的話,將消耗大量爬行預算,以至于一些重要的頁面可能就不能被收錄了。 使用robots.txt文件來幫助管理網(wǎng)站抓取預算,確保搜索引擎盡可能高效地(尤其是大型網(wǎng)站)抓取重要網(wǎng)頁而不是浪費時間去抓取登錄,注冊或支付頁面等頁面。 從搜索引擎優(yōu)化SEO的角度來看,robots.txt文件起著至關(guān)重要的作用。它告訴搜索引擎他們?nèi)绾巫詈玫刈ト∧愕木W(wǎng)站。 使用robots.txt文件可以阻止搜索引擎訪問網(wǎng)站的某些部分,防止重復內(nèi)容,并為搜索引擎提供有關(guān)如何更有效地抓取你網(wǎng)站的有用提示。 在對robots.txt進行更改時要小心:因為設(shè)置失誤可能會使搜索引擎無法訪問網(wǎng)站的大部分內(nèi)容。 在Googlebot,Bingbot等機器人抓取網(wǎng)頁之前,它會首先檢查是否存在robots.txt文件,如果存在,則通常會遵循該文件中找到的路線。 你可以通過robots.txt文件控制以下事情: 阻止訪問網(wǎng)站的某個部分(開發(fā)和登臺環(huán)境等) 保持網(wǎng)站內(nèi)部搜索結(jié)果頁面不被抓取,編入索引或顯示在搜索結(jié)果中 指定站點地圖或站點地圖的位置 通過阻止訪問低價值頁面來優(yōu)化抓取預算(登錄,支付頁面,購物車等) 防止將網(wǎng)站上的某些文件(圖像,PDF等)編入索引 讓我們看一個例子來說明這一點: 你有一個電子商務網(wǎng)站,訪問者可以使用篩選功能快速搜索你的產(chǎn)品,如通過銷量、價格排列。 此篩選生成的頁面基本上顯示與其他頁面相同的內(nèi)容。 這對用戶很有用,但會混淆搜索引擎,因為它會創(chuàng)建重復的內(nèi)容。 如果搜索引擎把這些網(wǎng)頁編入索引,將浪費你寶貴的抓取資源。 因此,應該設(shè)置規(guī)則,以便搜索引擎不訪問這些頁面。 如果你不熟悉robots.txt文件,或者不確定你的網(wǎng)站是否有該文件,可以快速查看。 方法: 將 /robots.txt 添加到首頁URL的末尾。 示例:www.yoursite.com/robots.txt 如果沒有顯示任何內(nèi)容,那么說明你的站點沒有robots.txt文件。那就應該設(shè)置一個了。 創(chuàng)建robots.txt文件是一個相當簡單的過程: 新建文本文檔 ——>重命名為robots.txt(所有文件必須小寫)——> 編寫規(guī)則 ——>用FTP把文件上(放到根目錄下)傳到空間 下面的文章是谷歌官方介紹,將向你robots.txt文件的創(chuàng)建過程,可以幫助你輕松建立你自己的robots.txt文件: https://support.google.com/webmasters/answer/6062596?hl=zh-Hans 注意: robots.txt自身是一個文本文件。它必須位于域名的根目錄中并 被命名為"robots.txt"。位于子目錄中的 robots.txt 文件無效,因為爬蟲只在域名的根目錄中查找此文件。 例如,http://www.example.com/robots.txt 是有效位置,http://www.example.com/mysite/robots.txt 則不是。 如果你用WordPress建站,可以用virtual robots、yoast、all in one seo等插件創(chuàng)建和設(shè)置。 以下是可以在自己的網(wǎng)站上使用robots.txt文件的幾個示例。 允許所有爬蟲 /蜘蛛訪問所有網(wǎng)站內(nèi)容: 禁止所有爬蟲 /蜘蛛訪問所有網(wǎng)站內(nèi)容: 這里可以了解到在創(chuàng)建站點robots.txt時出錯是多么容易,因為阻止整個站點被看到的區(qū)別在于:disallow指令(Disallow:/)中的簡單斜杠。 阻止谷歌爬蟲 /蜘蛛訪問: 阻止爬蟲 /蜘蛛訪問特定頁面: 從服務器的一部分中排除所有爬蟲: 一、說明theverge不想谷歌爬蟲去抓取這些目錄下的內(nèi)容 二、說明theverge不想任何爬蟲去抓取這些目錄下的內(nèi)容 三、theverge把所有的站點地圖列在robots.txt里面 可以在此處查看示例文件:www.theverge.com/robots.txt 可以看到The Verge如何使用他們的robots.txt文件,專門支出Google的新聞蜘蛛“Googlebot-News”(第一點),以確保它不會抓取網(wǎng)站上的這些目錄。 重要的是要記住,如果想確保爬蟲不會抓取你網(wǎng)站上的某些頁面或目錄,那么可以在robots.txt文件的“Disallow”聲明中調(diào)出這些頁面和/或目錄,如上面例示的做法。 另外,還可以在robots.txt規(guī)范指南中查看Google如何處理robots.txt文件,Google對robots.txt文件的當前最大文件大小限制。 Google的最大大小設(shè)置為500KB,因此請務必注意您的網(wǎng)站robots.txt文件的大小。 以下內(nèi)容提取于谷歌官方介紹,原文: https://support.google.com/webmasters/answer/6062596?hl=zh-Hans robots.txt文件應始終放在 請注意,robots.txt文件的URL與其他任何URL一樣,區(qū)分大小寫。 如果在默認位置找不到robots.txt文件,搜索引擎會認為沒有指令。 文件必須命名為 robots.txt。 網(wǎng)站只能有 1 個 robots.txt 文件。 robots.txt 文件必須位于它所應用到的網(wǎng)站主機的根目錄下。例如,要控制對? robots.txt 文件可應用到子網(wǎng)域(例如? robots.txt 必須是 ASCII 或 UTF-8 文本文件。不允許包含其他字符。 robots.txt 文件由一條或多條規(guī)則組成。 每條規(guī)則由多條指令(說明)組成,每條指令各占一行。 每條規(guī)則包含以下信息: 此規(guī)則的適用對象(即User-agent) 代理可以訪問的目錄或文件,和/或 代理無法訪問的目錄或文件。 系統(tǒng)會按照從上到下的順序處理這些規(guī)則,而且一個用戶代理只能匹配 1 個規(guī)則集(即與相應用戶代理匹配的首條最具體的規(guī)則)。 系統(tǒng)的默認假設(shè)是:用戶代理可以抓取所有未被? 規(guī)則區(qū)分大小寫。例如, User-agent: * Disallow: / User-agent: * Disallow: /calendar/ Disallow: /junk/ User-agent: Googlebot-news Allow: / User-agent: * Disallow: / User-agent: Unnecessarybot Disallow: / User-agent: * Allow: / User-agent: Googlebot-Image Disallow: /images/dogs.jpg User-agent: Googlebot-Image Disallow: / User-agent: Googlebot Disallow: /*.gif$ User-agent: * Disallow: / User-agent: Mediapartners-Google Allow: / User-agent: Googlebot Disallow: /*.xls$ 重要的是要注意搜索引擎處理robots.txt文件的方式不同。默認情況下,第一個匹配指令總是有優(yōu)先權(quán)。 但是Google谷歌和Bing必應,更偏重于具體的目錄。 就是說:如果指令的字符長度較長,則谷歌和必應會跟看重 例子 User-agent:* Allow:/ about / company / Disallow:/ about / 在上面的示例中 例子 User-agent:* Disallow:/ about / Allow:/ about / company / 在上面的示例中,除Google和Bing之外的所有搜索引擎都不允許訪問 但允許?Google和Bing?訪問 你只能為每個搜索引擎定義一組指令。為一個搜索引擎設(shè)置多組指令會使它們混淆。 disallow指令也會觸發(fā)部分匹配。 在定義 例子 User-agnet:* Disallow:/directory 上面的示例不允許搜索引擎訪問: /directory /directory/ /directory-name-1 /directory-name.html /directory-name.php /directory-name.pdf 所以要指明那個目錄是需要被禁止爬行的。 另外 網(wǎng)站管理員必須使蜘蛛程序遠離某些服務器上的目錄——保證服務器性能。比如:大多數(shù)網(wǎng)站服務器都有程序儲存在“cgi-bin”目錄下,因此在robots.txt文件中加入“Disallow: /cgi-bin”是個好主意,這樣能夠避免將所有程序文件被蜘蛛索引,可以節(jié)省服務器資源。一般網(wǎng)站中不需要蜘蛛抓取的文件有:后臺管理文件、程序腳本、附件、數(shù)據(jù)庫文件、編碼文件、樣式表文件、模板文件、導航圖片和背景圖片等等。 這個是什么意思? 讓我們看一個明確的例子: User-agent: * Disallow:/ secret / Disallow:/ test / Disallow:/ not-started-yet / User-agent:googlebot Disallow:/ not-started-yet / 在上面的示例中,除Google之外的所有搜索引擎都不允許訪問 Google不允許訪問 如果您不想讓googlebot訪問 User-agent:* Disallow:/ secret / Disallow:/ test / Disallow:/ not-started-yet / User-agent:googlebot Disallow:/ secret / Disallow:/ not-started-yet / 頁面仍出現(xiàn)在搜索結(jié)果中 由于robots.txt而導致搜索引擎無法訪問的網(wǎng)頁,但如果它們是從已抓取的網(wǎng)頁進行鏈接,則仍會顯示在搜索結(jié)果中。例子: Protip:可以使用Google Search Console的網(wǎng)址刪除工具從Google中刪除這些網(wǎng)址。請注意,這些網(wǎng)址只會被暫時刪除。為了讓他們不在Google的結(jié)果頁面中,需要每90天刪除一次網(wǎng)址。 緩存 谷歌表示robots.txt文件通常緩存最多24小時。在robots.txt文件中進行更改時,請務必考慮到這一點。 目前還不清楚其他搜索引擎如何處理robots.txt的緩存,但一般來說,最好避免緩存你的robots.txt文件,以避免搜索引擎花費超過必要的時間來接收更改。 文件大小 對于robots.txt文件,Google目前支持的文件大小限制為500 kb。可以忽略此最大文件大小之后的任何內(nèi)容。 可以在舊版谷歌站長工具進行檢查。 點擊? 抓取 > robots.txt測試工具 可以看到你的robots內(nèi)容,下面輸入想測試的url,點擊測試,就能知道該url是否有被robots.txt的指令給限制了。 https://support.google.com/webmasters/answer/6062598?hl=zh-Hans 確保所有重要頁面都是可抓取的 不要阻止網(wǎng)站JavaScript和CSS文件 在站長工具檢查重要的URL是否被禁止抓取 正確大寫目錄,子目錄和文件名 將robots.txt文件放在網(wǎng)站根目錄中 Robots.txt文件區(qū)分大小寫,文件必須命名為“robots.txt”(沒有其他變體) 請勿使用robots.txt文件隱藏私人用戶信息,因為它仍然可見 將站點地圖位置添加到robots.txt文件中。 這看起來像這個 store.yoursite.com/robots.txt和yoursite.com/robots.txt。 原因是,其他頁面可能鏈接到該信息,如果有直接鏈接,它將繞過robots.txt規(guī)則,并且內(nèi)容可能仍會被索引。 如果您需要阻止您的網(wǎng)頁在搜索結(jié)果中真正被編入索引,請使用不同的方法,例如添加密碼保護或向這些網(wǎng)頁添加noindex元標記。Google無法登錄受密碼保護的網(wǎng)站/網(wǎng)頁,因此他們無法抓取或索引這些網(wǎng)頁。 雖然有人說 谷歌尚未明確原因,但我們認為我們應該認真對待他們的建議,因為: 如果使用多種方式發(fā)出不索引的信號,那么很難跟蹤哪些頁面不應該被索引。 該 我們只知道Google使用該 如果你之前從未使用過robots.txt文件,可能會有點緊張,但請放心使用,而且設(shè)置相當簡單。 一旦熟悉了文件的細節(jié),就可以增強網(wǎng)站的搜索引擎優(yōu)化。 通過正確設(shè)置robots.txt文件,將幫助搜索引擎爬蟲明智地花費他們的抓取預算,并幫助確保他們不浪費時間和資源來抓取不需要抓取的網(wǎng)頁。 這將有助于他們以盡可能最好的方式在SERP中組織和顯示你的網(wǎng)站內(nèi)容,意味著你將獲得更多的曝光。 設(shè)置robots.txt文件并不一定需要花費大量的時間和精力。在大多數(shù)情況下,它是一次性設(shè)置,然后可以進行一些小的調(diào)整和更改,以幫助更好地塑造網(wǎng)站。 我希望本文中介紹的做法、提示和建議有助你著手創(chuàng)建/調(diào)整你的網(wǎng)站robots.txt文件。 1. 百度蜘蛛:Baiduspider網(wǎng)上的資料百度蜘蛛名稱有BaiduSpider、baiduspider等,都洗洗睡吧,那是舊黃歷了。百度蜘蛛最新名稱為Baiduspider。日志中還發(fā)現(xiàn)了Baiduspider-image這個百度旗下蜘蛛,查了下資料(其實直接看名字就可以了……),是抓取圖片的蜘蛛。常見百度旗下同類型蜘蛛還有下面這些:Baiduspider-mobile(抓取wap)、Baiduspider-image(抓取圖片)、Baiduspider-video(抓取視頻)、Baiduspider-news(抓取新聞)。注:以上百度蜘蛛目前常見的是Baiduspider和Baiduspider-image兩種。 2. 谷歌蜘蛛:Googlebot這個爭議較少,但也有說是GoogleBot的。谷歌蜘蛛最新名稱為“compatible; Googlebot/2.1;”。還發(fā)現(xiàn)了Googlebot-Mobile,看名字是抓取wap內(nèi)容的。 3. 360蜘蛛:360Spider,它是一個很“勤奮抓爬”的蜘蛛。 4、SOSO蜘蛛:Sosospider,也可為它頒一個“勤奮抓爬”獎的蜘蛛。 5、雅虎蜘蛛:“Yahoo! Slurp China”或者Yahoo!名稱中帶“Slurp”和空格,名稱有空格robots里名稱可以使用“Slurp”或者“Yahoo”單詞描述,不知道有效無效。 6、有道蜘蛛:YoudaoBot,YodaoBot(兩個名字都有,中文拼音少了個U字母讀音差別很大嘎,這都會少?) 7、搜狗蜘蛛:Sogou News Spider搜狗蜘蛛還包括如下這些: Sogou web spider、Sogou inst spider、Sogou spider2、Sogou blog、Sogou News Spider、Sogou Orion spider,(參考一些網(wǎng)站的robots文件,搜狗蜘蛛名稱可以用Sogou概括,無法驗證不知道有沒有效)看看最權(quán)威的百度的robots.txt ,http://www.baidu.com/robots.txt 就為Sogou搜狗蜘蛛費了不少字節(jié),占了一大塊領(lǐng)地。“Sogou web spider;Sogou inst spider;Sogou spider2;Sogou blog;Sogou News Spider;Sogou Orion spider”目前6個,名稱都帶空格。線上常見”Sogou web spider/4.0″ ;”Sogou News Spider/4.0″ ;”Sogou inst spider/4.0″ 可以為它頒個“占名為王”獎。 8、MSN蜘蛛:msnbot,msnbot-media(只見到msnbot-media在狂爬……) 9、必應蜘蛛:bingbot線上(compatible; bingbot/2.0;) 10、一搜蜘蛛:YisouSpider 11、Alexa蜘蛛:ia_archiver 12、宜sou蜘蛛:EasouSpider 13、即刻蜘蛛:JikeSpider 14、一淘網(wǎng)蜘蛛:EtaoSpider“Mozilla/5.0 (compatible; EtaoSpider/1.0; http://省略/EtaoSpider)”根據(jù)上述蜘蛛中選擇幾個常用的允許抓取,其余的都可以通過robots屏蔽抓取。如果你暫時空間流量還足夠使用,等流量緊張了就保留幾個常用的屏蔽掉其它蜘蛛以節(jié)省流量。至于那些蜘蛛抓取對網(wǎng)站能帶來有利用的價值,網(wǎng)站的管理者眼睛是雪亮的。 另外還發(fā)現(xiàn)了如 YandexBot、AhrefsBot和ezooms.bot這些蜘蛛,據(jù)說這些蜘蛛國外,對中文網(wǎng)站用處很小。那不如就節(jié)省下資源。 Peace Out 給我【在看】 你也越好看!
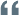
User-agent:*
Disallow:User-agent:*
Disallow:/User-agent:Googlebot
Disallow:/User-agent:
Disallow:/thankyou.htmlUser-agent:*
Disallow:/ cgi-bin /
Disallow:/ tmp /
Disallow:/junk/這是theverge.com網(wǎng)站上robots.txt文件的示例:
位置規(guī)則和文件名
root網(wǎng)站的位置(在主機的頂級目錄中)并帶有文件名robots.txt,例如:https://www.example.com/robots.txt。
http://www.example.com/?下所有網(wǎng)址的抓取,就必須將 robots.txt 文件放在根目錄下(即?http://www.example.com/robots.txt),而不能放在子目錄下(例如?http://example.com/pages/robots.txt)。http://website.example.com/robots.txt)或非標準端口(例如?http://example.com:8181/robots.txt)。語法
Disallow:?規(guī)則禁止訪問的網(wǎng)頁或目錄。Disallow: /file.asp?適用于?http://www.example.com/file.asp,但不適用于?http://www.example.com/FILE.asp。
規(guī)則
示例
禁止抓取整個網(wǎng)站。?請注意,在某些情況下,Google 即使未抓取網(wǎng)站的網(wǎng)址,仍可能會將其編入索引。注意:這不適用于各種 AdsBot 抓取工具,此類抓取工具必須明確指定。
禁止抓取某一目錄及其內(nèi)容(在目錄名后面添加一道正斜線)。請注意,若想禁止訪問私密內(nèi)容,則不應使用 robots.txt,而應改用適當?shù)纳矸蒡炞C機制。對于 robots.txt 文件所禁止抓取的網(wǎng)址,Google 仍可能會在不進行抓取的情況下將其編入索引;另外,由于 robots.txt 文件可供任何人隨意查看,因此可能會泄露您的私密內(nèi)容的位置。
僅允許使用某一抓取工具
允許使用除某一抓取工具以外的其他所有抓取工具
禁止抓取某一網(wǎng)頁(在正斜線后面列出網(wǎng)頁):
Disallow: /private_file.html
禁止 Google 圖片訪問某一特定圖片:
禁止 Google 圖片訪問您網(wǎng)站上的所有圖片:
禁止抓取某一特定類型的文件(例如 .gif):
禁止抓取整個網(wǎng)站,但允許在這些網(wǎng)頁上顯示 AdSense 廣告(禁止使用除 Mediapartners-Google 以外的所有網(wǎng)頁抓取工具)。這種方法會阻止您的網(wǎng)頁顯示在搜索結(jié)果中,但?Mediapartners-Google?網(wǎng)頁抓取工具仍能分析這些網(wǎng)頁,以確定要向您網(wǎng)站上的訪問者顯示哪些廣告。
匹配以某一特定字符串結(jié)尾的網(wǎng)址?- 需使用美元符號 ($)。例如,示例代碼會禁止訪問以 .xls 結(jié)尾的所有網(wǎng)址:
優(yōu)先順序
Allow指令。/about/,除了子目錄之外,所有搜索引擎(包括Google和Bing)都不允許訪問該目錄/about/company/。/about/目錄,包括/about/company/。/about/company/,因為該Allow指令比Disallow指令長,目錄位置更具體。指令
User-agent:[必需,每條規(guī)則需含一個或多個 User-agent 條目] ,填寫搜索引擎蜘蛛(抓取工具)的名稱。這是每條規(guī)則的首行內(nèi)容。Web Robots Database 和 Google User Agent(抓取工具)列表中列出了大多數(shù)用戶代理名稱。支持使用星號 (*) 通配符表示路徑前綴、后綴或整個字符串。像下例中那樣使用星號 (*) 可匹配除各種 AdsBot 抓取工具之外(此類抓取工具必須明確指定)的所有抓取工具。示例:# 示例 1:僅屏蔽 Googlebot
User-agent: Googlebot
Disallow: /
# 示例 2:屏蔽 Googlebot 和 Adsbot
User-agent: Googlebot
User-agent: AdsBot-Google
Disallow: /
# 示例 3:屏蔽除 AdsBot 抓取工具之外的所有抓取工具
User-agent: *
Disallow: /Disallow:[每條規(guī)則需含至少一個或多個 Disallow 或 Allow 條目] 用戶代理不應抓取的目錄或網(wǎng)頁(相對于根網(wǎng)域而言)。如果要指定網(wǎng)頁,就應提供瀏覽器中顯示的完整網(wǎng)頁名稱;如果要指定目錄,則應以標記“/”結(jié)尾。支持使用通配符“*”表示路徑前綴、后綴或整個字符串。Allow:[每條規(guī)則需含至少一個或多個 Disallow 或 Allow 條目] 上文中提到的用戶代理應抓取的目錄或網(wǎng)頁(相對于根網(wǎng)域而言)。此指令用于替換 Disallow 指令,從而允許抓取已禁止訪問的目錄中的子目錄或網(wǎng)頁。如果要指定網(wǎng)頁,就應提供瀏覽器中顯示的完整網(wǎng)頁名稱;如果要指定目錄,則應以標記“/”結(jié)尾。支持使用通配符“*”表示路徑前綴、后綴或整個字符串。Sitemap:[可選,每個文件可含零個或多個 Sitemap 條目] 相應網(wǎng)站的站點地圖的位置。必須是完全限定的網(wǎng)址;Google 不會假定存在或檢查是否存在 http/https/www/非 www 等網(wǎng)址變體。站點地圖是一種用于指示 Google 應抓取哪些內(nèi)容(而不是可以或無法抓取哪些內(nèi)容)的好方法。詳細了解站點地圖。?示例:Sitemap: https://example.com/sitemap.xml
Sitemap: http://www.example.com/sitemap.xml要盡可能具體
Disallow指令時盡可能具體,以防止無意中禁止訪問文件。
特定User Agent的指令,不包含在所有User Agent抓取工具的指令
/secret/,/test/和/not-launched-yet/。/not-launched-yet/,但允許訪問/secret/和/test/。/secret/,/not-launched-yet/,那么需要googlebot特別重復這些指令:檢查robots.txt文件和URL
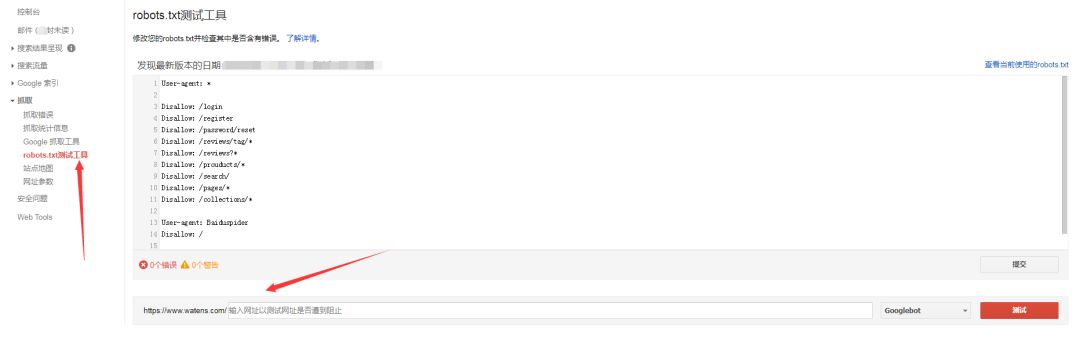
如果你有一個子域或多個子域在網(wǎng)站,那么你將需要對每個子域以及在主根域robots.txt文件。
不要在robots.txt中使用noindex
noindex在robots.txt文件中使用指令是個好主意,但它不是官方標準,谷歌公開建議不要使用它。
noindex指令不是萬無一失的,因為它不是官方標準。可能它不會被谷歌100%追蹤。noindex指令,其他搜索引擎(可能)不會將其用于noindex頁面。
獲取更多國外SEM、SEO干貨




文章為作者獨立觀點,不代表DLZ123立場。如有侵權(quán),請聯(lián)系我們。( 版權(quán)為作者所有,如需轉(zhuǎn)載,請聯(lián)系作者 )

網(wǎng)站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優(yōu)質(zhì)的學習資料。
現(xiàn)在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)