網頁索引增加的10種辦法
?
一般來說正常的網站內容都能夠被谷歌搜索引擎收錄并添加到其索引數據庫中,只不過每個網站頁面可能因為頁面質量、搜索用戶體驗、網站域名權重等因素的影響會導致被索引的時間存在一定的差異。但實際情況下,很多同學還是在為自己的網站頁面遲遲不能被谷歌索引而感到頭疼。那么,今天Jack老師就和大家一起來學習一下 網頁索引增加的10種方法 。
方法一:刪除 robots.txt 文件中禁止爬取代碼
robots.txt是一種存放于網站根目錄下的ASCII編碼的文本文件,它通常告訴網絡搜索引擎的漫游器(又稱網絡蜘蛛),此網站中的哪些內容是不應被搜索引擎的漫游器獲取的,哪些是可以被漫游器獲取的。因為一些系統中的URL是大小寫敏感的,所以robots.txt的文件名應統一為小寫。那么這個文件怎么設置或者改寫呢?通過ftp軟件遠程連接或者直接登錄直接網站的后臺服務器,找到根目錄下的該文件,然后進行改寫。
我們再來看一下robots.txt文件的寫法:
User-agent: * 這里的*代表的所有的搜索引擎種類,*是一個通配符
Disallow: /admin/ 這里定義是禁止爬尋admin目錄下面的目錄
Disallow: /require/ 這里定義是禁止爬尋require目錄下面的目錄
Disallow: /ABC/ 這里定義是禁止爬尋ABC目錄下面的目錄
Disallow: /cgi-bin/*.htm 禁止訪問/cgi-bin/目錄下的所有以”.htm”為后綴的URL(包含子目錄)。
Disallow: /*?* 禁止訪問網站中所有包含問號 (?) 的網址
Disallow: /.jpg$ 禁止抓取網頁所有的.jpg格式的圖片
Disallow:/ab/adc.html 禁止爬取ab文件夾下面的adc.html文件。
Allow: /cgi-bin/ 這里定義是允許爬尋cgi-bin目錄下面的目錄
Allow: /tmp 這里定義是允許爬尋tmp的整個目錄
Allow: .htm$ 僅允許訪問以”.htm”為后綴的URL。
Allow: .gif$ 允許抓取網頁和gif格式圖片
Sitemap: 網站地圖 告訴爬蟲這個頁面是網站地圖
比方說我們要禁止百度的蜘蛛來爬取我們網站的頁面內容,那robots.txt文件應該怎么寫呢?如下所示。
User-agent: Baiduspider
Disallow: /
如果我們又突然改變主意,想允許它爬取我們的內容,又該怎么寫呢?如下所示。
User-agent: Baiduspider
Allow: /
方法二:移除noindex代碼
但我們在做wordpress網站的時候,一般會在設置中的閱讀功能下設置“暫不對搜索引擎可見”,這時候如果你去查看網站任何一個頁面的源代碼(用ctrl+u快捷鍵,或者鼠標右鍵點擊查看網頁源代碼),你會在源代碼中看到noindex的存在。
這個代碼告訴了搜索引擎不要將該頁面內容添加到谷歌的索引數據庫中。在做完網站之后,我們很可能忘記了最初的這個網站功能設置,導致自己的網站頁面遲遲的不能被索引。所以在網站內容檢查無誤準備放開收錄的時候,這里的功能一定要取消,如下圖所示。

?
還有一種noindex的情況比較特殊,那就是X?Robots-Tag標頭。X-Robots-Tag?可用作指定網址的 HTTP 標頭響應中的一個元素。可在漫游器元標記中使用的任何指令均可被指定為?X-Robots-Tag。下面是一個 HTTP 響應示例,它含有一個指示抓取工具不要將某一網頁編入索引的?X-Robots-Tag:

這一點可能對同學們比較陌生,我們可以使用Ahrefs工具的“站點審核工具”來進行操作,如下圖所示。

如果對這個項目不是很明白的同學,建議先點擊查看一下這方面的知識,鏈接如下
漫游器元標記知識拓展入口
方法三:在站點地圖中包含該頁面
站點地圖告訴 Google 你網站上的哪些頁面重要,哪些不重要。它還可能會就應重新抓取它們的頻率提供一些指導。Google 應該能夠在你的網站上找到頁面,無論它們是否在你的站點地圖中,但將它們包含在內仍然是一種很好的做法。
畢竟,讓谷歌的抓取工作變得困難是沒有意義的。要檢查某個頁面是否在你的站點地圖中,請使用Search Console 中的網址檢查工具。如果你看到“網址不在 Google 上”錯誤和“站點地圖:不適用”這些報錯情況,那么說明某個網站頁面不在你的站點地圖中或尚未編入索引。
一般來說,如果你安裝了yoast seo或者math rank等谷歌SEO優化插件,它們都會為你主動生成網站的sitemap,你只需要將這些sitemap主動提交到網站的google search console中即可。提交完成之后,你可以順手做一個ping提交指令,如下所示:
https://www.google.com/ping?sitemap=http://www.domain.com/sitemap_url.xml
方法四:刪除流氓規范標簽
規范標簽告訴 Google 哪個是頁面的首選版本。它看起來像這樣:
<link rel="canonical” href="/page.html/">
大多數頁面要么沒有規范標簽,要么沒有所謂的自引用規范標簽。這告訴 Google 頁面本身是首選的,也可能是唯一的版本。換句話說,你希望谷歌搜索引擎將此頁面編入索引。但是,如果你的頁面有一個流氓規范標簽,那么它可能會告訴 Google 該頁面的首選版本不存在。
在這種情況下,你的頁面不會被編入索引。如果你想要檢查URL網址規范,那么請使用 Google 的URL檢查工具。如果規范指向另一個頁面,那么你將會看到“帶有規范標記的備用頁面”警告,如下所示。
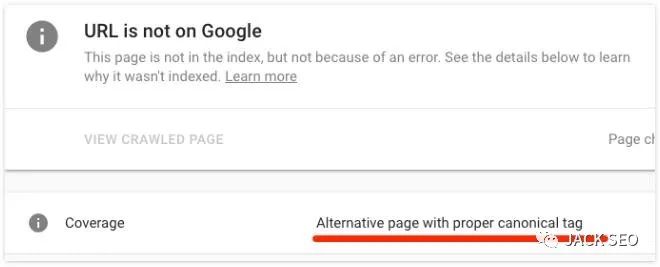
需要注意的是:規范標簽并不總是壞的。大多數帶有這些標簽的頁面都會有它們。如果看到你的頁面具有規范集,請檢查規范頁面。如果這確實是頁面的首選版本,并且不需要為相關頁面建立索引,那么規范標簽應該保留。
方法五:檢查孤立頁面
孤立頁面是那些沒有內部鏈接指向它們的頁面。或者說當前的某個頁面沒有任何的鏈接方式通往自己網站的其他頁面。常見于一些landing page頁面,甚至都沒有菜單導航欄的存在。
由于 Google 通過抓取網絡來發現新內容,因此他們無法通過該過程發現孤立頁面。網站訪問者也無法找到它們。要檢查孤立頁面,可以使用Ahrefs 的站點審核來抓取網站頁面。然后檢查?“孤立頁面(沒有傳入的內部鏈接)”錯誤的鏈接報告,如下圖所示。

當然了,市面上還是有很多其他的url檢測工具也有非常強大的功能,比方說尖叫青蛙,Check box等等。利用這些工具也能夠為自己的網站檢測出沒有做任何鏈接指向其他頁面的“孤立頁面”。
好了,以上就是 網頁索引增加的10種辦法 上半部分的內容,下半部分內容將在下一章節中進行講解,敬請期待。
如果對本章內容還有不理解的地方,沒關系,解決方案如下:
百度或者谷歌瀏覽器搜索???“JACK外貿建站”,排名首頁首位的就是我的網站。網站上有更多免費的外貿建站、谷歌SEO優化、外貿客戶開發等實操干貨知識等著你哦!
(各位看官老爺,都看到這里了,就麻煩動動金手點擊轉發一下本文到自己的微信朋友圈吧,轉發過程如下)
QQ:3233269705
QQ群:645296397
微信公眾號:JACK?SEO

文章為作者獨立觀點,不代表DLZ123立場。如有侵權,請聯系我們。( 版權為作者所有,如需轉載,請聯系作者 )

網站運營至今,離不開小伙伴們的支持。 為了給小伙伴們提供一個互相交流的平臺和資源的對接,特地開通了獨立站交流群。
群里有不少運營大神,不時會分享一些運營技巧,更有一些資源收藏愛好者不時分享一些優質的學習資料。
現在可以掃碼進群,備注【加群】。 ( 群完全免費,不廣告不賣課!)